Original research
Who's Blocking AI Crawlers? What 10,000 robots.txt Files Show

Most of the web’s biggest sites still let AI crawlers in. But the ones pulling up the drawbridge are making a surprisingly specific choice about which AI gets access, and it’s not the choice I expected.
I checked the robots.txt of the top 10,000 sites in the Majestic Million to see how many allow or block the major AI crawlers, which bots get blocked most, and whether the bigger players are more protective.
{kind=link}
How I read 10,000 robots.txt files
I fetched /robots.txt for each of the top 10,000 domains and parsed it the way a compliant crawler does, matching each bot to its most specific user-agent group and checking whether that group allows or blocks the site root.
Not every site gives a clean answer. Some sit behind bot protection that refused the request, some timed out, and some returned an error page instead of a file. I set those aside rather than guess. That leaves 7,870 sites with a determinable result: either a readable robots.txt, or a clean 404, which means no rules and an open door by default. Every percentage below is out of those 7,870.
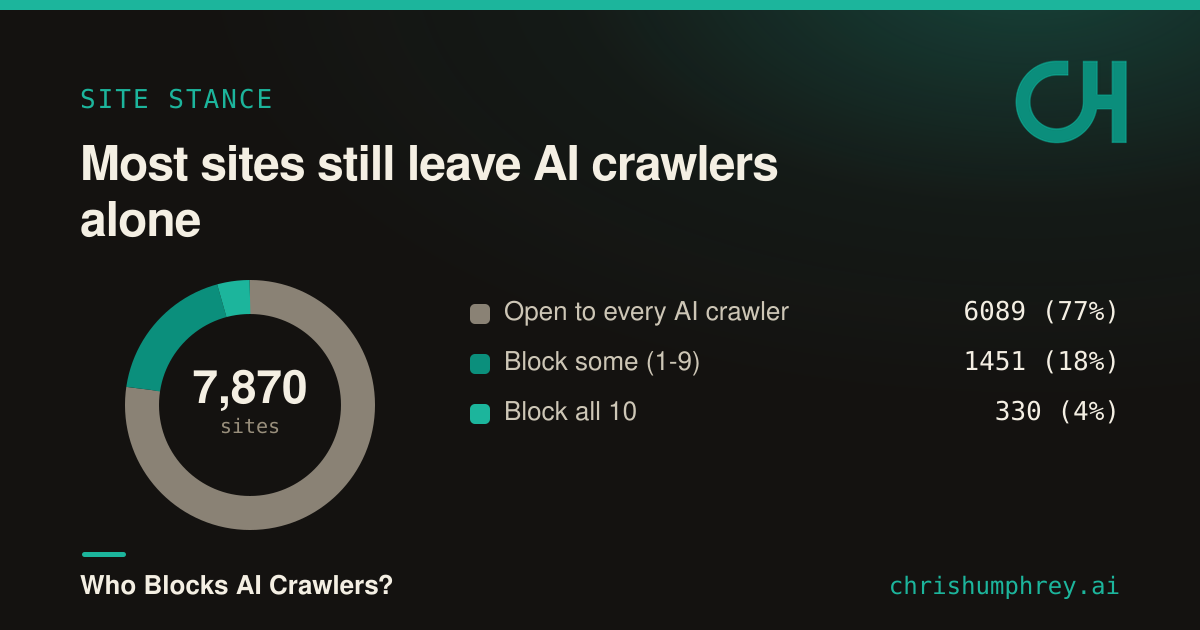
Most sites still leave AI crawlers alone
The headline is reassuring if you’re rooting for an open web: 77% of these sites are open to every major AI crawler. About 22.6% block at least one, and only 330 sites block all ten I checked.
- Open to every AI crawler 6089 (77%)
- Block some (1-9) 1451 (18%)
- Block all 10 330 (4%)
{kind=link}
So blocking is a minority behavior. But who gets blocked, and by whom, is where it gets interesting.
Training crawlers get blocked, search crawlers get a pass
Here’s the part I didn’t expect. When sites block, they overwhelmingly block the crawlers that collect data for model training, while leaving the crawlers that power AI search and citations alone.
The clearest proof is within a single company. OpenAI runs two crawlers: GPTBot, which gathers training data, and OAI-SearchBot, which builds the index ChatGPT cites when it searches the web. Holding the company constant removes any “people just trust one lab over another” explanation, and what’s left is a clean split.
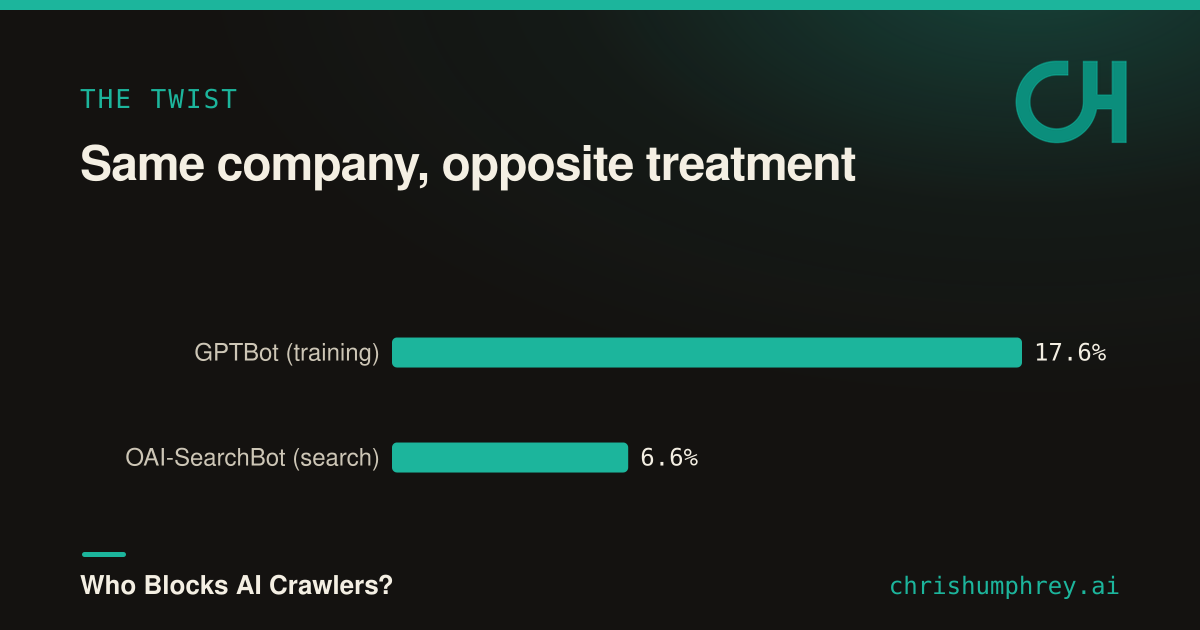{kind=link}
Sites are nearly three times more willing to be cited than to be trained on. And it isn’t just OpenAI: the same split runs across every lab.
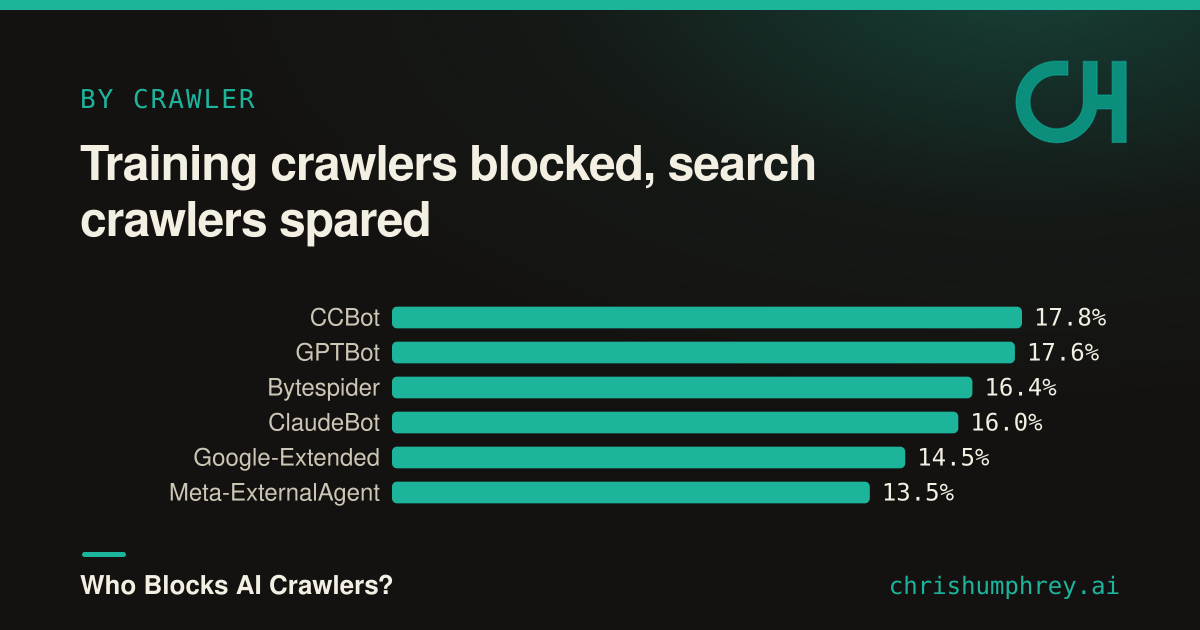{kind=link}
The most-blocked crawlers (CCBot, GPTBot, Bytespider, ClaudeBot, Google-Extended) are all training collectors, and the least-blocked are the ones tied to live search and answers. One nuance on the leader: Common Crawl’s CCBot has been around since 2011, so some of its blocks predate the AI moment and reflect old bandwidth decisions rather than a fresh call on training. The pattern doesn’t lean on it, though. GPTBot, a purpose-built AI training crawler, sits right behind. Whether sites are doing this deliberately or just copying blocklists that circulated when “block AI” meant “block training,” the effect is the same: they’re protecting their content from being learned while staying open to being found.
Bigger sites block more
Blocking also tracks with size. The top 500 sites block an AI crawler about a third of the time, while the rate drifts down to roughly 20% in the 5,000 to 10,000 range.
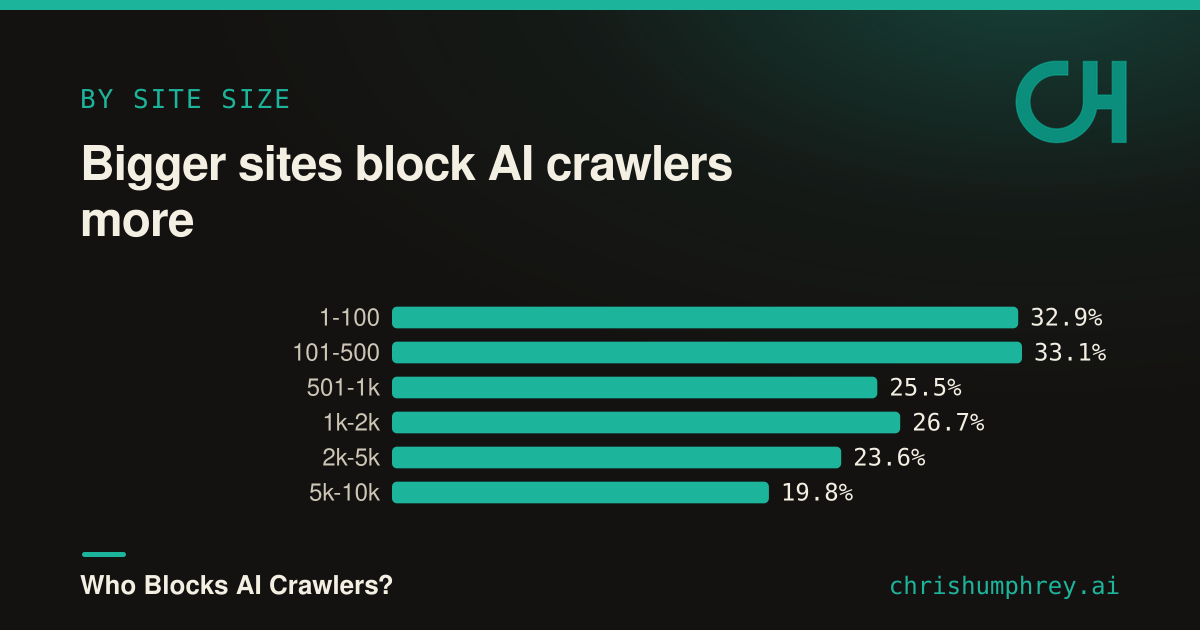{kind=link}
That fits what you’d expect. Larger sites are more likely to be publishers with content-licensing concerns, to have legal teams with opinions, and to have the resources to manage bot policy at all. Smaller sites mostly haven’t touched the question. The very top tiers are small samples, though (the top 100 is only 85 sites with a clear answer), so I’d read the broad gradient here, not the exact tier-by-tier order.
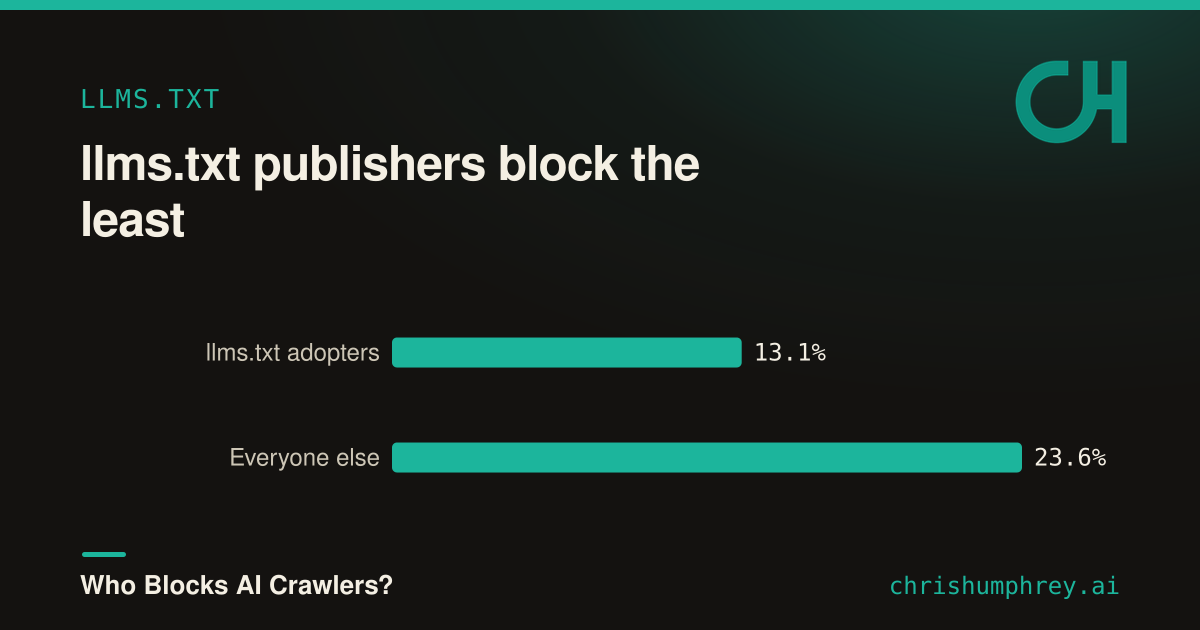
llms.txt publishers block the least
One cross-reference, since I had the data from a companion study. Sites that publish an llms.txt file, an explicit invitation for AI tools to read them, block an AI crawler only 13.1% of the time, versus 23.6% for everyone else.
{kind=link}
That’s the consistency you’d hope for: the sites rolling out a welcome mat are also the ones leaving the door unlocked. It’s the inverse of the contradiction I found in the llms.txt study, where a small slice did both at once. One caveat: this is a correlation, not proof of cause. llms.txt adopters are a self-selected, AI-friendly group, so the gap probably says more about who they already are than about what publishing the file does to them.
So what should you do?
Decide your AI crawler policy on purpose, then make robots.txt say exactly that.
If you want to be found and cited in AI answers, which most brands competing for visibility do, the search and live-fetch crawlers are the ones that matter, and blocking them quietly removes you from those surfaces. Training crawlers are a separate, legitimate decision: blocking them keeps your content out of future models, at the cost of those models knowing less about you.
The common mistake is doing it by accident, with an old blanket rule that catches more than you meant. If you’re not sure what yours allows, the AI Crawler Access Checker reads your live robots.txt and tells you, bot by bot.
A note on the data
This is a snapshot of the top 10,000 Majestic Million domains, crawled in June 2026. robots.txt is a stated policy, not an enforcement mechanism: compliant crawlers honor it, but some (Bytespider has been widely reported to ignore it) do not, so a block here is an instruction, not a guarantee. The 2,130 sites without a determinable robots.txt are left out of every rate above. If you want the underlying data or have a question about the method, get in touch.
Working through the same shift?
I write about SEO, GEO, and getting found by AI search.
If this was useful, I'd love to compare notes.