
There are a lot of confident numbers floating around about llms.txt adoption. I wanted to see the real picture, so I measured it directly.
I crawled the top 10,000 sites in the Majestic Million, pulled every llms.txt that exists, and read what was inside. Here is what the data shows, including a few things I did not expect.
{kind=link}
The short version of the method: I fetched /llms.txt for the top 10,000 domains in the Majestic Million in June 2026, followed redirects so apex and www both count, and kept only files that were genuinely Markdown rather than HTML. One caveat up front: the top 10,000 by backlink profile skews toward established, technical, SEO-aware sites, so read this as one well-defined slice, not the whole web.
New to llms.txt? Start with my plain-English guide to what it is and how to write one. This piece is about what the data says.
How I measured llms.txt adoption
A status code alone isn’t enough to trust. Plenty of sites return a clean 200 OK for /llms.txt and then serve their homepage or an error page as HTML, with no real file behind it. That’s a soft 404: the server reports success, but there’s nothing actually there. Count those as adopters and the number gets inflated.
Across the top 10,000, 1,050 sites returned a 200 for /llms.txt, but about a third of them (313) turned out to be soft 404s, serving an HTML page rather than a real Markdown file. The 737 that served an actual file are the real adopters.
So the honest number is 737 sites, or 7.4%.
Everything below uses that cleaned figure. If a study reports a much higher number, it’s worth asking whether they filtered out the soft 404s.
How widespread is adoption?
Adoption numbers for llms.txt swing wildly with the sample. Ahrefs, looking at a traffic-weighted set of sites in their analytics (which skews technical and SEO-aware, and which they call an upper bound), reported 28%. This study looks at the top 10,000 sites by backlink profile and finds 7.4%. Same screening standard, different populations, very different numbers. So the useful thing here is not one universal percentage, it is the shape of adoption inside a defined, high-authority slice of the web.
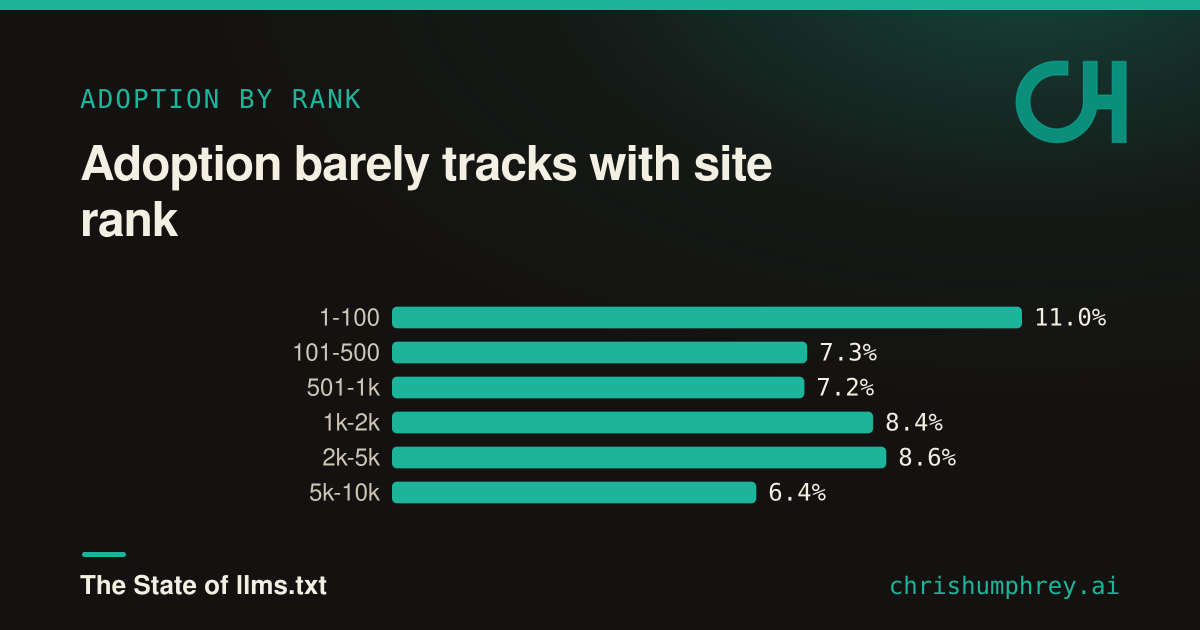
And the shape held a surprise: adoption barely tracks with rank.
{kind=link}
The top 100 lead at 11%, but after that it flattens out and wobbles between 6% and 9% all the way down to rank 10,000. The 2,000 to 5,000 tier actually adopts more than the 500 to 1,000 tier. This is not a clean “bigger sites adopt more” story. It is closer to a thin, even layer of early adopters spread across the whole top tier, which tells me this is still driven by individual awareness, not any kind of industry default.
Most llms.txt files are custom, for now
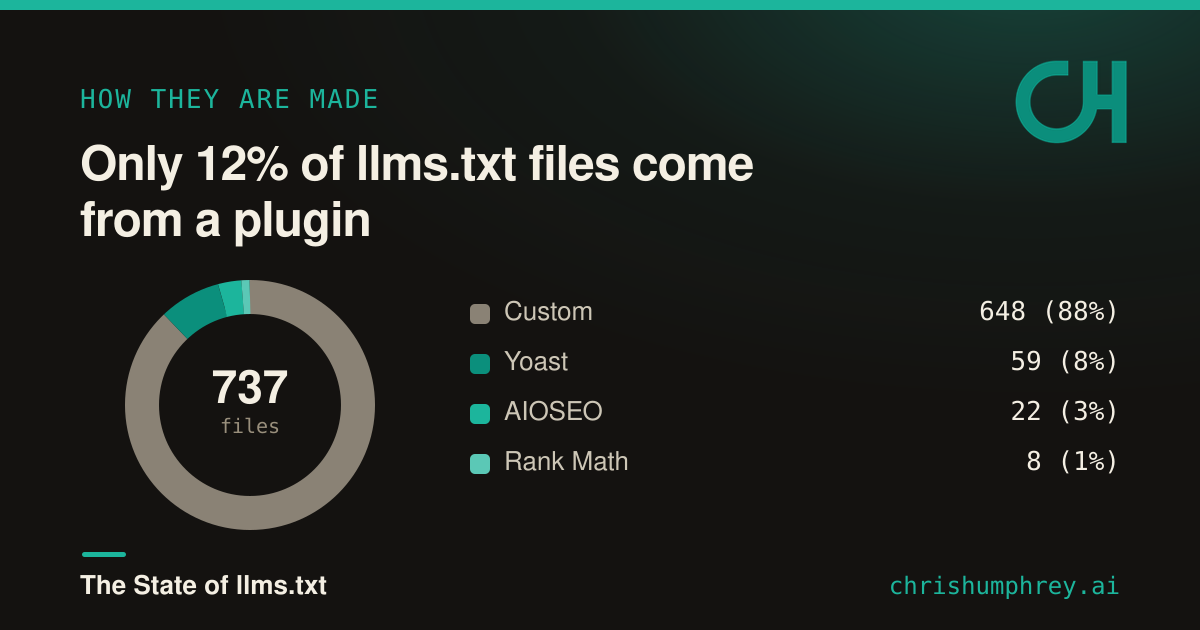
Here is the finding I keep coming back to. Of the 737 real files, only 12% are generated by an SEO plugin. The other 88% have no plugin fingerprint at all. I am calling those custom rather than handcrafted on purpose: some are genuinely written by hand, but others are produced with AI or some other tool. The honest line is just that they did not come from one of the SEO plugins that auto-generate this file.
- Custom 648 (88%)
- Yoast 59 (8%)
- AIOSEO 22 (3%)
- Rank Math 8 (1%)
{kind=link}
I detected generators by their own attribution line, the one plugins write into the file, like Generated by All in One SEO or Generated by Yoast SEO. That is far more reliable than guessing from a site’s tech stack, and it caught a few files that the lazier method would have mislabeled.
Among the plugins, Yoast leads by a wide margin: 59 files, versus 22 for AIOSEO and 8 for Rank Math. All three are general-purpose SEO plugins, which suggests plugin-driven adoption is riding on tooling sites already run rather than anything llms.txt-specific.
That 12% is the number to watch. Custom files appear one decision at a time. Plugin adoption grows every time a plugin ships the feature on by default. The day a major plugin flips that switch, this chart changes overnight.
Only just over half use the full structure
A file existing is not the same as a file being useful, so it is worth being precise about what “good” means. The spec is short. The only strictly required element is an H1 with the site or project name. On top of that it recommends a blockquote summary, then one or more sections of curated [name](url) links, with an optional section literally labeled Optional for things that can be skipped.
I checked every real file for that full recommended shape: a title, a summary, and at least one section of real links. Just 55% have all three. The other 45% are missing pieces: no summary, no real sections, or a flat wall of links with no structure. Auto-generated files are a big part of that gap. A plugin dumping every page, post, and category into one list technically produces a file, but it is not the curated map the format was designed to be.
This is the gap, and it is an opportunity. If you are going to publish one, publishing a good one still puts you ahead of nearly half the sites that already have one.
Blocking the crawlers they invited
This is the one that made me laugh, then wince.
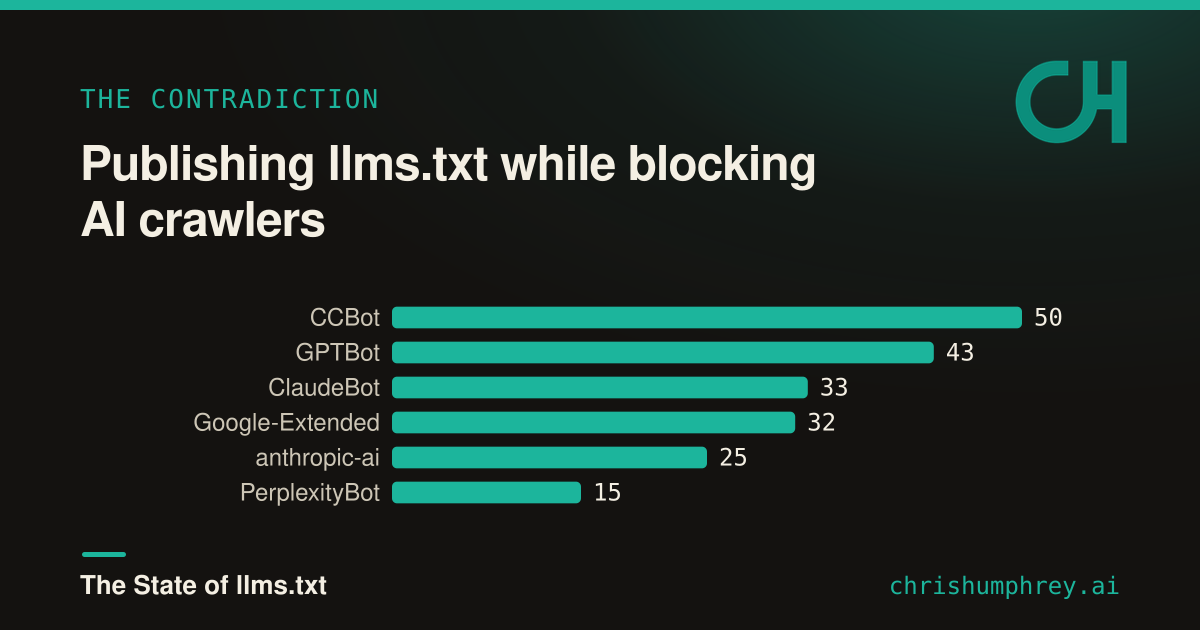
llms.txt exists to help AI crawlers understand your site. So I cross-referenced every adopter’s robots.txt to see whether they also block the major AI bots. 57 of the 737, about 8%, publish an llms.txt while actively blocking AI crawlers in robots.txt.
{kind=link}
A lot of them are publishers: weather.com, coindesk, msnbc, hackernoon, linktr.ee. They have rolled out a welcome mat for AI and bolted the front door at the same time. In most cases I would bet the two decisions were made by different people who never talked to each other, which is its own lesson about how this stuff actually gets deployed.
If you take one operational thing from this post: whatever you decide about AI crawlers, decide it once and make robots.txt and llms.txt agree.
What’s inside a typical llms.txt file
A couple of quick texture notes for anyone building one.
Size is wildly bimodal. The median file is about 7 KB, a tidy curated guide, but the range runs from a literal empty file to one that is 38 MB, which is what happens when a CMS dumps an entire site into a single text file. The value is in the curation, not the volume.
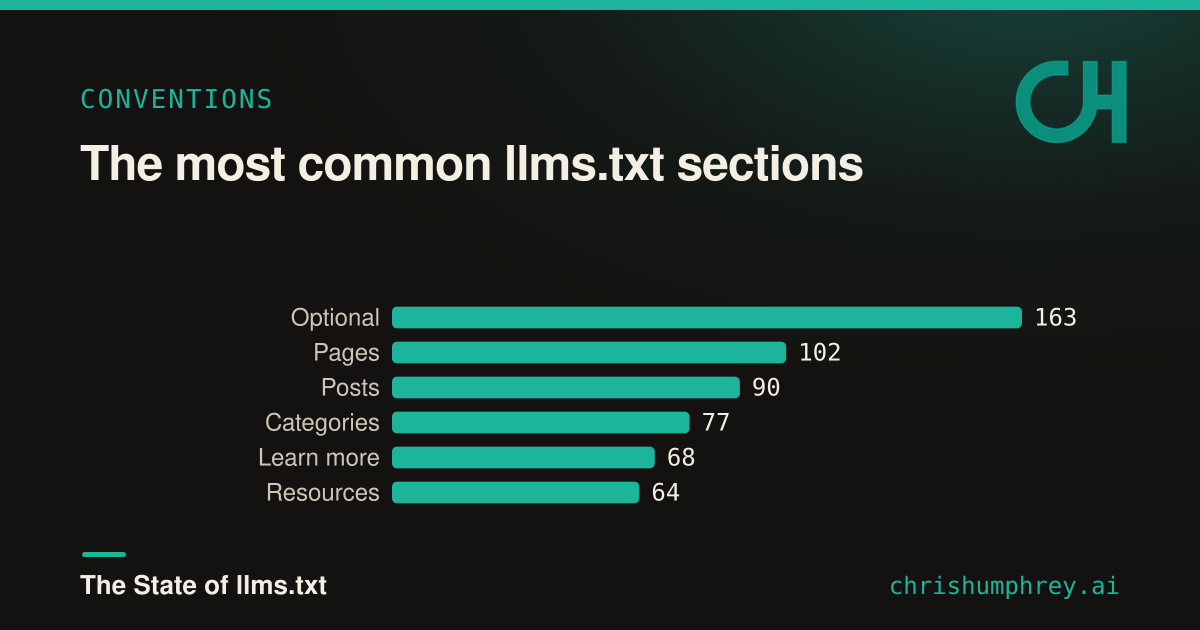
The section headings reveal the emerging conventions. The most common is Optional, which is straight from the spec. After that you see the CMS fingerprints (Pages, Posts, Categories) and then the genuinely useful curated sections (Resources, Products, Features).
{kind=link}
And who is publishing? Technology and SaaS companies lead by a wide margin, followed by media and publishing, e-commerce, and education.
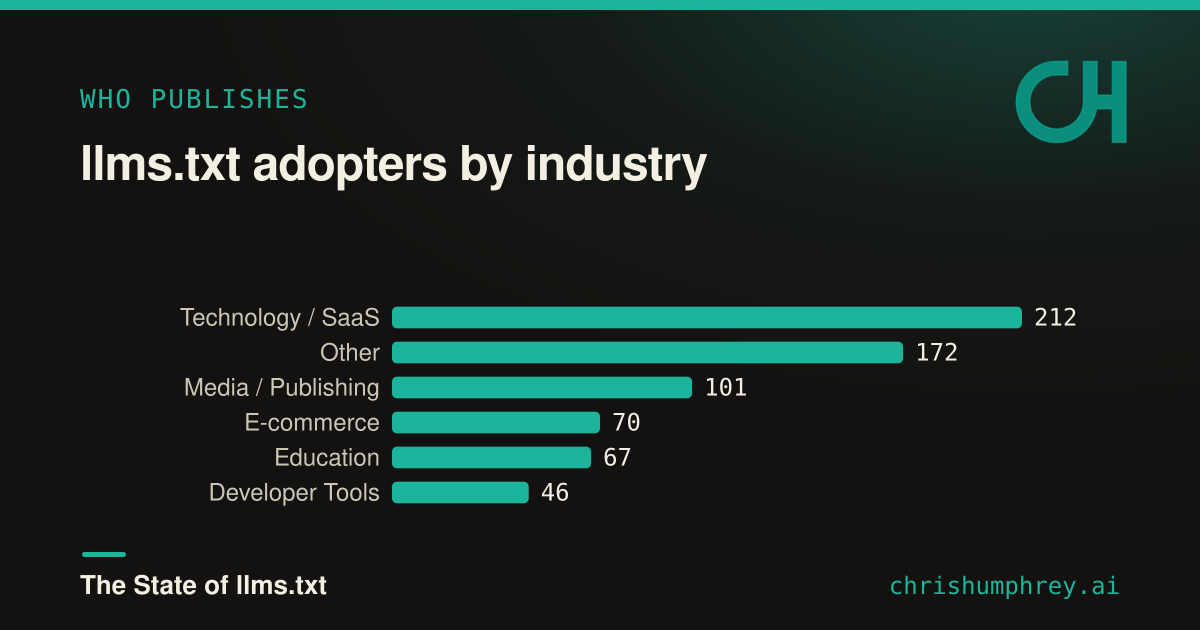{kind=link}
Should you publish an llms.txt?
Before anything else, be clear about what it is for. In June 2026 Google confirmed that Search does not use llms.txt, and that having one will neither help nor hurt your Google rankings. The audience is the AI tools and agents that opt to read it, plus checks like Chrome’s Lighthouse agentic-browsing audit. This is not a ranking hack. It is about giving the systems that do read it a clean map of your site.
With that in mind, yes, it is worth doing, on two conditions.
First, make it a real one. Curate it. Title, summary, a handful of well-chosen sections pointing at the pages you actually want represented. You will already be in better shape than the 45% who shipped something malformed.
Second, make your signals agree. If you are publishing an llms.txt, do not turn around and block the crawlers in robots.txt. Pick a posture and make it consistent.
I built two free tools for exactly this. The llms.txt generator helps you write a clean, spec-correct file in a few minutes. The AI crawler access checker shows you which AI bots your robots.txt currently allows or blocks, so you can catch the contradiction before you ship it.
A note on the data
This is a snapshot of the top 10,000 Majestic Million domains, crawled in June 2026. I plan to re-run it and track how these numbers move, because the interesting part of an emerging standard is the slope, not the single reading. If you want the underlying adopter list or have a question about the method, get in touch.
Working through the same shift?
I write about SEO, GEO, and getting found by AI search.
If this was useful, I'd love to compare notes.